Classification-Based Cache Replacement Policies
基于分类的策略学习对即将插入的 cacheline 进行二元分类:
一次 cache 访问是否可能导致未来的 hit ?
- Cache-friendly lines——即预期会导致 hit的 cacheline —— 会以更高的优先级插入cache,以便它们有充足的机会获得 cache hit
- Cache-averse lines——即预期不会导致hit 的 cacheline —— 则以低优先级插入,以便它们能被快速,从而不浪费 cache 资源
与其他替换策略相比,基于分类的策略优势:
- 与混合替换策略(在给定时间段内对同一 set 内所有 cachelines 做出统一决策)相比,基于分类的策略可以以高优先级插入某些 cacheline ,而以低优先级插入其他 cacheline
- 与基于重用距离的策略(其目标是预测一个数值化的重用距离)相比,基于分类的策略解决的是一个更简单的二元预测问题
基于分类的策略起源于两个不同的体系:
- SDBPKhan 等人建立在 dead block 预测的基础上
- SHiPWu 等人则根植于 cache 替换策略
基于分类的策略的共同特征:
- 都包含一个二元预测器,该预测器学习过去的 cache 行为,以指导单个 cacheline 的插入优先级
- 都借鉴了最先进的粗粒度策略中的 promption、aging 和 eviction 方案,有助于它们应对不准确的预测
基于分类的策略需要考虑的设计问题:
- 该策略学习的是哪种 cache 解决方案?
- 预测机制是什么,预测是在何种粒度上进行的?
- 用于确保不准确的预测最终被踢出的 aging 机制是什么?
Sampling Based Dead Block Prediction (SDBP, 2010)
由于 LLC 中的大多数块都是 Dead Block (它们在被踢出前不会被再次重用),因此可以利用 Dead Block 预测来指导 cache 替换和 Dead Block 的提前旁路
Lai 等人提出了使用 Dead Block 预测器将数据预取到 L1 Dead Block 中的想法
他们的 reftrace 预测器预测,如果一个指令地址轨迹导致了对某个 cacheline 的最后一次访问,那么相同的轨迹也将导致对其他 cacheline 的最后一次访问
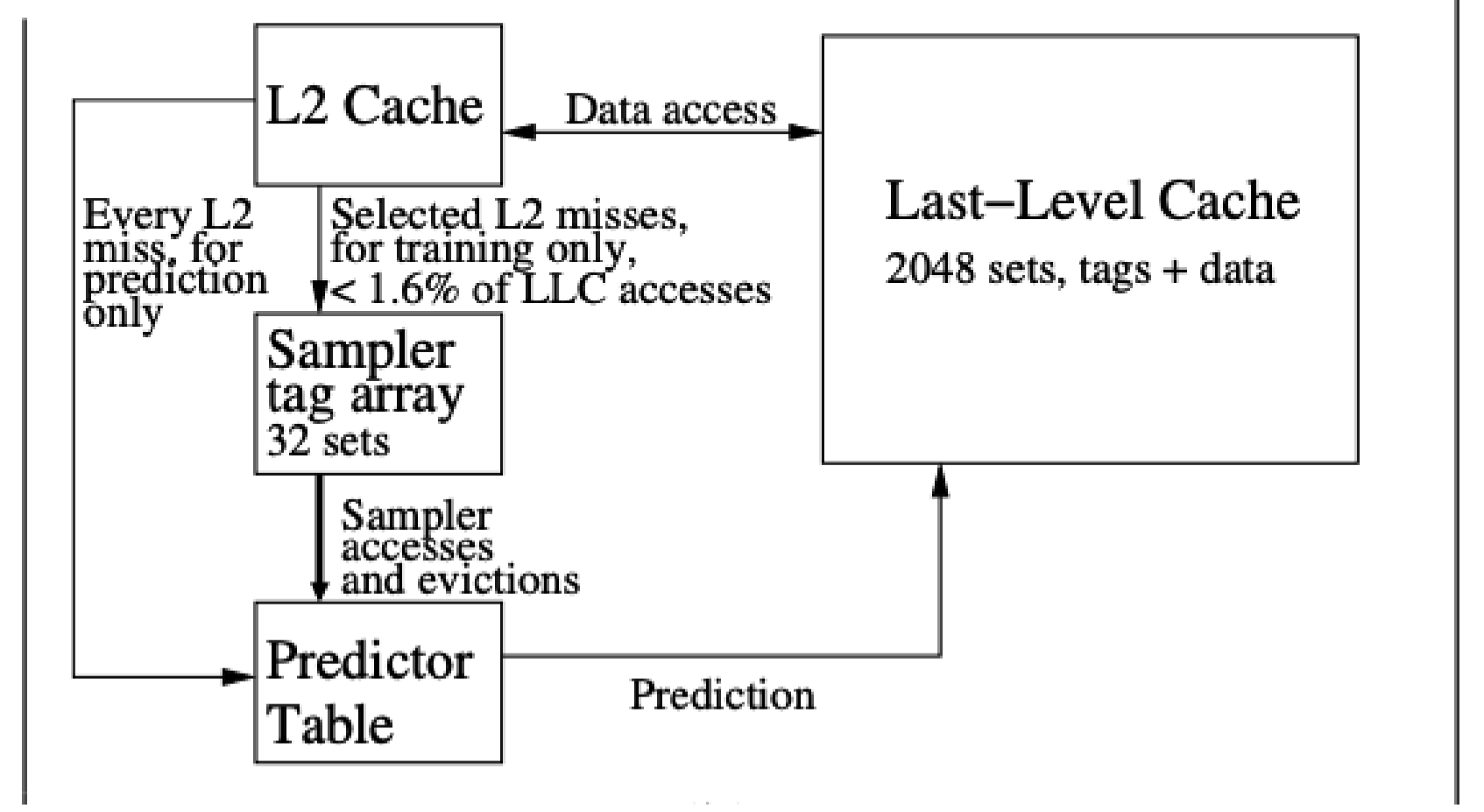
为了降低为所有 cacheline 维护指令轨迹的成本,Khan 等人引入了基于采样的 Dead Block 预测器(SDBP)
- 它采样 PC 的 cache 访问行为,以确定一个即将进入的 cacheline 是否可能是 Dead Block
- 来自已知会插入 Dead Block 的 PC 的 cache 访问将被旁路,以免污染 cache
- 来自不会插入 Dead Block 的 PC 的访问则使用某种基准策略(随机或 LRU 替换策略)插入 cache
SDBP 从一个解耦采样器学习,该采样器仅使用一小部分 cache 访问来填充。如果一个块从采样器中被踢出且未被重用,则对应的PC 会被负向训练;否则,预测器会被正向训练
解耦采样器的特点:
- 预测器仅使用所有 cache 访问中的一小部分样本来训练,这使得预测器设计和采样器中元数据(每个采样器条目都维护着 PC)的管理对于功耗和空间都比较高效
- 采样器的替换策略不必与 cache 的替换策略匹配。SDBP 对采样器使用 LRU 策略,而对主 cache 使用随机替换
- 采样器的相联度独立于主 cache 的相联度,这允许采用成本更低的采样器设计。SDBP 为一个 16 路 cache 使用了一个 12 路采样器
| Insertion | Promotion | Aging | Victim Selection |
|---|---|---|---|
| dead_bit = prediction MRU position |
dead_bit = prediction MRU position |
Increment LRU counter by 1 | Line with dead_bit = 1 or LRU position |
总结
- SDBP 学习基于 LRU 的采样器的 cache 决策
- 它使用一种有偏的预测器设计来预测 Dead Block(Cache-Averse vs. Cache-Friendly),并在 PC 粒度上做出这些预测
- SDBP 绕过所有被预测为 cache-averse 的传入
Signature Based Hit Prediction (SHiP)
与 SDBP 类似,SHiP 学习底层替换策略的 eviction 行为,但 SHiP 的主要思路是,重用行为与将 line 插入 cache 中的 PC 的关联性,比与最后访问该 line 的 PC 的关联性更强
- 在 cache eviction 发生时,SHiP 的预测器使用在 cache miss 时首次插入该 line 的 PC 进行训练,并且仅在 cache miss 时查询预测器(在 hit 时,cacheline 会被提升至最高优先级,无需查询预测器)
SHiP训练一个预测器,以学习给定的 signature 是否具有近或远的重引用间隔
- 在 cache 中采样少数几个 set 来维护 signature 并训练预测器
- 在采样 sets 中发生 cache hit 时,与该 cacheline 关联的 signature 会得到正向训练,以指示近重引用
- 在踢出一个从未被重用的 cacheline 时,其 signature 会得到负向训练,以指示远重引用
- 当插入新 cacheline 时,会使用其 signature 来查询预测器,并确定其重引用间隔(预测针对所有访问进行,而不仅仅是采样 sets)
- 一旦插入 cache ,cacheline 便使用简单的RRIP 策略进行管理
Signature 的选择对 SHiP 的有效性至关重要
经评估(PC signature、memory region signature , instruction sequences history signature ),PC signature 的表现最佳
SHiP 建立在 DRRIP 之上以创建一种细粒度策略
- DRRIP 为一个时期内的所有 cacheline 做出统一的重新引用预测
- SHiP则做出更细粒度的预测:通过将每次引用与一个唯一的 signature 相关联,将新进入的 cacheline 分类到不同的 groups 中。具有相同 signature 的 cacheline 被假定具有相似的重新引用行为
| Insertion | Promotion | Aging | Victim Selection |
|---|---|---|---|
| if(prediction) RRPV=2 else RRPV=3 |
RRPV = 0 | Increment all RRPVs (if no line with RRPV=3) |
RRPV = 3 |
总结
- SHiP 从 SRRIP 学习,但一旦 SHiP 的预测器训练完成,后续的训练更新则来自SHiP自身的重用和 eviction 行为
- SHiP使用一个基于 PC 的预测器,其中与 cacheline 关联的 PC 是在 cache miss 时插入该 cacheline 的指令 PC,每个 PC 关联一个饱和计数器
- SHiP 依赖 RRIP 策略来老化所有 cacheline
Hawkeye (2016)
为了避免基于启发式解决方案(如 LRU)的问题,Hawkeye 基于 Belady 的 MIN 策略构建,有两个原因:
- Belady 的 MIN 算法对于任何引用序列都是最优的,因此基于 MIN 的解决方案适用于任何访问模式
- Belady 的 MIN 算法是一种硬件不可实现的算法,因为它会替换未来最久才会被重用的行,依赖于对未来的预知
Hawkeye 的核心思路是:
- 虽然无法预知未来,但可以将 Belady 的 MIN 算法应用于过去的内存访问记录
- 如果一个程序过去的行为是其未来行为的良好预测器,那么通过学习过去的最优解,Hawkeye 可以训练出一个预测器,对未来的访问表现良好
为了理解模拟 MIN 算法处理过去事件需要多少历史信息,通过限制其未来窗口来研究 MIN 的性能
实验显示,虽然 MIN 需要一个很长的未来窗口(对于 SPECint 2006 来说,窗口大小相当于 8 倍 cache 容量),但它并不需要一个无限的窗口
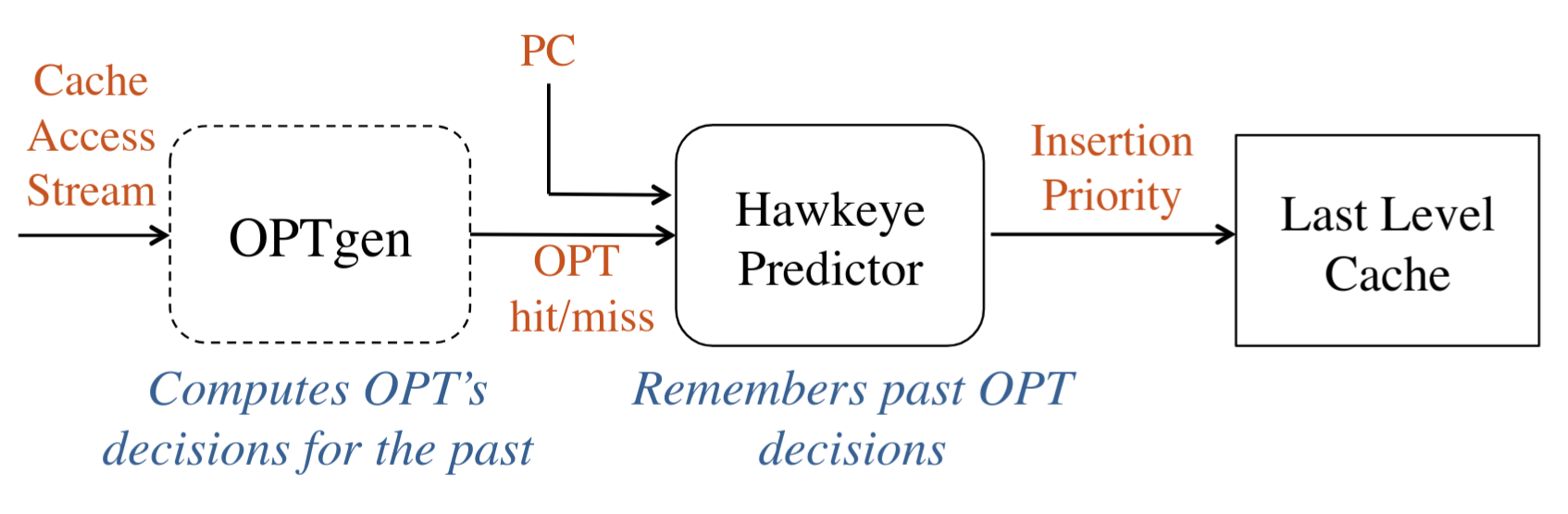
由于维护一段 8倍历史信息的成本太高,Hawkeye 仅针对少数采样集计算最优解,并引入了 OPTgen 算法:
- 该算法为这些采样集计算出与 Belady 的 MIN 策略相同的答案
- OPTgen 确定了如果使用 MIN 策略,哪些行本应被保留
- OPTgen 的关键思想是,当一行数据被再次使用时,可以准确地确定其最优缓存决策
- 在每次重用时,OPTgen 回答在 MIN 策略下,这一行本应是 cache hit or miss?
这使得 OPTgen 能够以 O(n) 的复杂度,使用少量硬件预算和简单的硬件操作,重现 Belady 的方案
OPTgen 用于训练 Hawkeye 预测器,这是一个基于 PC 的预测器,用于学习由特定 PC 插入的 cacheline 倾向于 cache-friendly or cache-averse
当 OPTgen 判定某一 cacheline 在 MIN 策略下本应 hit 时,则对该 cacheline 对应的 PC 进行正向训练,否则进行负向训练
对于每一次 cache 插入和提升操作,都会根据新进 cacheline 的 PC 来查询该预测器
被预测为 cache-friendly 的 line 将以高优先级插入
被预测 cache-averse 的 line 则以低优先级插入
| Insertion | Promotion | Aging | Victim Selection |
|---|---|---|---|
| if(prediction) RRPV=0 else RRPV=7 |
(same as insertion) | Increment all RRPVs (if no line with RRPV=7) |
RRPV = 7 |
总结:
- Hawkeye 从最优 cache 方案中学习,而不是从 LRU 或 SRRIP 中学习
- Hawkeye 使用基于 PC 的预测器来学习最优解,在概念上类似于 SDBP 和 SHiP 中使用的预测器
- Hawkeye 也依赖 RRIP 的老化机制,来老化那些以高优先级插入的行。为了纠正不准确的预测,当一条被预测为 cache-averse 的 line 在未被重用时就被踢出时,Hawkeye 也会对预测器进行负向训练。(Hawkeye 将 cache 替换表述为一个监督学习问题)
- 与分支预测不同(程序执行最终会提供每个分支的正确结果),硬件 cache 并不提供此类数据。通过对过去事件应用最优解,Hawkeye 提供了标注数据,这表明 cache 替换领域或许能从监督学习的广泛研究中受益
Perceptron-Based Prediction (2016)
预测策略在很大程度上依赖于其预测器的准确性。SDBP、SHiP 和 Hawkeye 都使用基于 PC 的预测器,准确率大约在 70‑80% 之间。
Perceptron Predictor (2016)
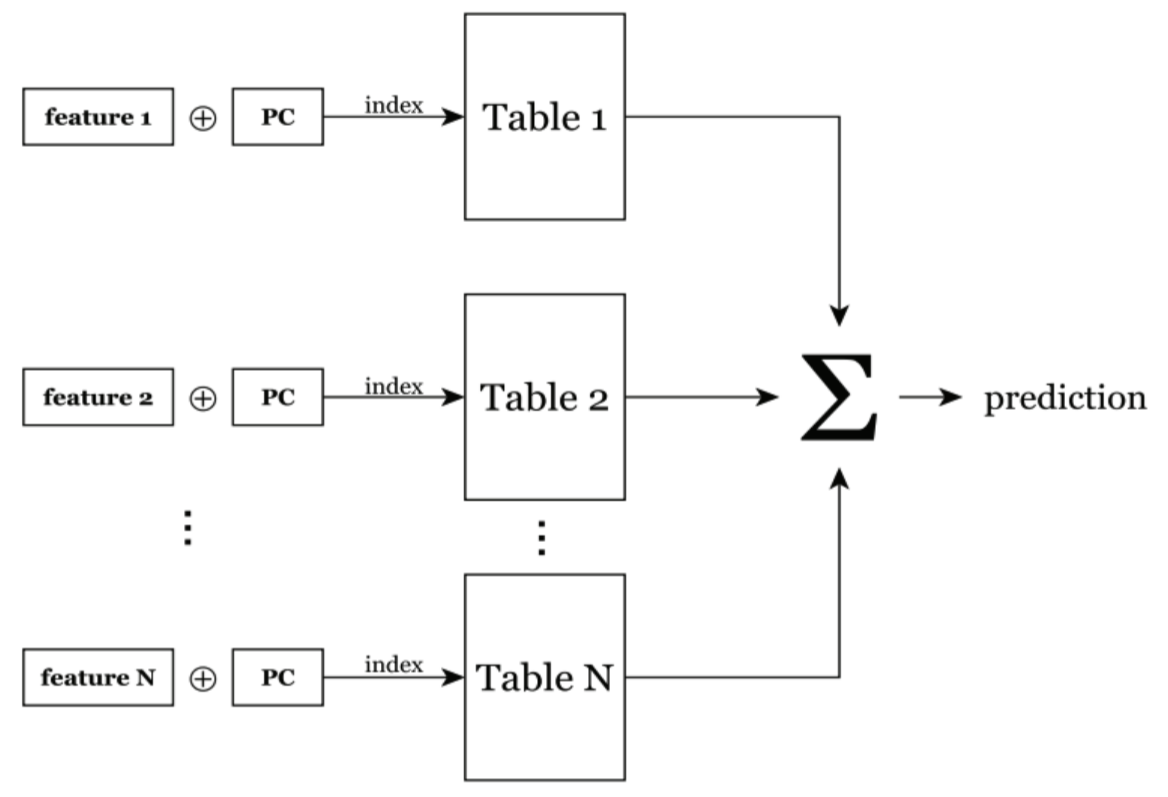
感知器预测器使用简单的人工神经元来使 PC 具有更丰富的信息,例如:
- PC的历史信息
- 来自内存地址的 bits
- 数据的压缩表示
- 一个 cacheline 被访问的次数
每个特征用于索引一个独立的饱和计数器表,然后将这些计数器求和并与一个阈值比较,以生成一个二元预测
一小部分访问被采样,用于根据感知器更新规则更新感知器预测器:如果预测不正确,或者总和未能超过某个幅度,则在访问时递减计数器,在踢出时递增计数器
Multiperspective Reuse Predictor (2017)
多视角重用预测器探索了一套广泛的特征集,这些特征捕捉了程序的各种属性,从而产生了一个从多个视角获取信息的预测器。这些特征通过更丰富的信息进行参数化,包括每个训练输入的 LRU stack 位置、每个特征进行哈希运算所用的 pc bits,以及 pc 历史信息的长度。这些参数共同创建了一个庞大的特征空间,从而带来了更高的预测准确度。
Evicted Address Filter (EAF, 2012)
EAF 策略会单独预测每个 miss cacheline 的重用行为,从而提供比 PC 更细粒度的区分
其关键观察是:
- 如果一个具有高重用性的 cacheline 被过早地从 cache 中踢出,那么它将在被踢出后很快被再次访问;
- 而一个低重用性的 cacheline 在被踢出后很长时间内都不会被访问
因此,EAF 策略使用一个 Bloom Filter(一种用于判断集合中元素是否存在、概率性且空间高效的数据结构)来追踪一小部分最近被踢出的地址
- 当发生 cache miss 时,如果新 cacheline 存在于 bloom filter(也称为 Evicted Address Filter, EAF)中,则该 cacheline 被预测为具有重用友好性,并以高优先级插入
- 否则,新 cacheline 将根据 BIP 插入策略进行插入
当 Bloom Filter 已满时,会被重置
EAF 在概念上类似于一个小的 victim cache ,用于追踪最近从主 cache 中被踢出的 cacheline
| Insertion | Promotion | Aging | Victim Selection |
|---|---|---|---|
| MRU position (if in EAF), BIP (otherwise) |
MRU position | Increment by 1 | LRU position |
EAF 策略将 cacheline 的生命周期延长至被踢出之后, 因此一个 cacheline 的生命周期始于其插入,但结束于该行从 EAF 中移除之时
通过扩展生命周期,EAF 得以观察具有较长重用间隔的行的重用情况,这带来了更好的扫描抵抗性和更好的颠簸抵抗性,从而提升了性能
Reuse Detector (ReD, 2017)
重用检测器 Reuse Detector 采用类似的想法:(类似于 cache 中的 stream buffer)
- 它会绕过任何在 LLC 或 Address Reuse Table 中 miss 的 cacheline
- Address Reuse Table 会追踪近期的 cache misses
- ReD 仅在第二次重用时才将 cacheline 插入 cache
为避免在首次看到所有 cacheline 时都将其绕过,
ReD 使用了一个基于 PC 的预测器来预测那些可能在首次访问后被重用的 cacheline