GPU Overview
内容参考自:General-Purpose Graphics Processor Architecture
硬件架构
在现代系统中,GPU 不是单独的计算设备,需要和 CPU 一起在一个系统中工作,有 2 种协同工作方式:
- 集成到单个芯片当中
- 将 GPU 视为一张卡插入到含有 CPU 的系统中
在这个系统中,CPU 的任务是:初始化 GPU 的计算任务,和 GPU 之间进行数据交互
将 CPU 和 GPU 的功能分离开来,是因为:
- 在计算的开始和结束通常需要访问 IO 设备
- 现在的一些工作致力于直接为 GPU 提供 IO 访问的 API, 但仍基于一个前提:GPU 存在于 CPU 的附近
- 这些 API 隐藏了 CPU 和 GPU 之间通信管理的复杂性,而不是为了完全替代 CPU
- CPU 可以提供 IO 设备的访问和对操作系统服务的请求
不同线程数下的计算架构的性能建模图: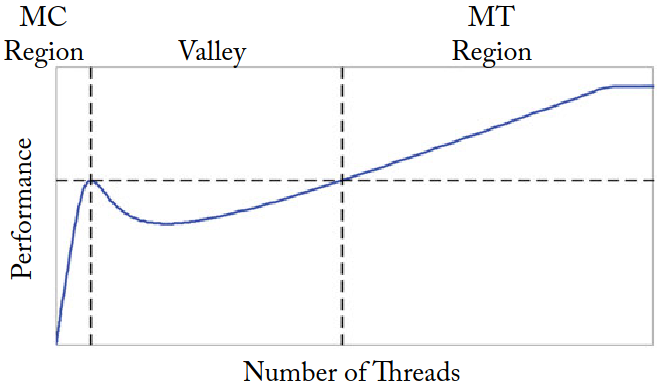
- MC(multicore) Region: 当较少的线程数共享一个大的 cache 时,随着线程数上升,性能显著提升
- Valley: 之后随着线程数增加,cache 无法容纳整个工作负载,性能下降
- MT(multithreading) Region: 当线程数足够多时,高吞吐率可以掩盖片外访存延时,性能上升
GPU 与 CPU 系统架构
- System with discrete GPU

- CPU 和 GPU 之间通过总线连接
- CPU 和 GPU 有分离的DRAM 存储空间
- CPU 中称为 system memory 系统内存,通常使用 DDR 实现,主要优化目标是降低访问时延
- GPU 中称为 graphics memory 显存,通常使用 GDDR 实现,主要优化目标是提高吞吐量
- Integrated CPU and GPU

- 一般用于低功耗设备
- 共享一个 DRAM 存储空间,通常使用 LPDDR 实现
CPU 和 GPU 的交互: CPU 初始化计算
GPU 计算程序中的 CPU 部分首先运行,负责分配和初始化数据结构
- NVIDIA 和 AMD 一些古老的 discrete GPU
- 需要在 CPU 和 GPU 的内存中均分配数据结构
- CPU 需要协调从 CPU 内存到 GPU 显存的数据搬运
- 最新的 discrete GPU
- 软硬件支持数据自动从 CPU 内存到 GPU 显存搬运 (需要 CPU 和 GPU 均支持虚拟内存, unified memory)
- Integrated GPU 由于共享内存不需要考虑内存搬移
- 但 CPU 和 GPU 的私有 cache 之间需要考虑 Cache Coherence 问题
初始化过程通过运行在 CPU 上的驱动程序完成,在执行 GPU 计算之前,需要指定以下内容,并通过驱动程序传递给 GPU 中:
- kernel to run: 哪些代码应该在 GPU 上运行
- number of threads: 运行多少个线程
- data location: 线程在哪里查找输入数据
初始化完成,驱动程序会向 GPU 发送信号,表明可以开始进行计算。
GPU 架构

SIMT Core
现代 GPU 中存在大量的 SIMT Core (NVIDIA 称为 SM, Streaming Multiprocessors; AMD 称为 Compute Units)
- 每个 SIMT Core 执行 kernel 中的一个 SIMT 程序
- 每个 SIMT Core 中的线程可以通过 SPM (scratchpad memory) 通信并使用快速 barrier 操作实现同步
- 每个 SIMT Core 一般还包括 L1 Instruction/Data Cache
Memory Channel
为匹配 SIMT Core 中的极高的计算吞吐率,也需要极高的访存带宽(访存并行度),这通过提供大量的 memory channels 实现
- 每个 memory channel 和 LLC 中的一个 Partition 相连 (类似于 CPU Memory Hierarchy 中的 Shared Distributed LLC Banks)
- LLC Memory Partitions 和 SIMT Cores 通过片上网络互联通信
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.