文件系统 File System
文件系统API
文件(file)
低级名称:inode 号(inode number)
内容:vector<char>
文件描述符(file descriptor): 指向操作系统对象的指针
通过指针可以访问 “everything”,是一个整数,每个进程私有
与其他系统调用的交互:
- fork 时会被子进程继承
- execve 时文件描述符不变
文件偏移(offset): 文件的读写自带 “游标”
Offset 管理:
- read/write: 会自动维护 offset
- lseek: 修改 offset 位置
与其他系统调用的交互:
- open 时,获得一个独立的 offset
- dup 时,两个文件描述符共享 offset
- fork 时,父子进程共享 offset (UNIX)
文件syscall API
- 创建文件:open()
- 构建一个数据结构(inode)
- 将人类可读的名称链接到该文件
- 将该链接放入目录中
- 读写文件
- read() & write()
- 修改偏移量:lseek()
- 强制立即写入fsync()
出于性能的原因,write()在内存中会缓冲一段时间再写入
- 文件重命名:rename()
属于原子(atomic)调用 - 获取文件信息:stat() & fstat()
- 删除文件:unlink()
删除人类可读名字与inode之间的引用关系,引用计数-=1
引用计数 == 0时,才会释放inode 和相关数据块
目录(directory)
低级名称:inode 号(inode number)
内容: 均为元数据(metadata),可以指向其他目录或文件
内容:std::map<filename, inumber>
目录syscall API
- 创建目录:mkdir()
- 读取目录
- readdir():每调用一次读取一个dirent
- getdents():返回 count 个目录项
- 删除目录:rmdir()
链接 (link)
硬链接
对同一个 inode 号创建了新的引用 (不以任何方式复制)
允许一个文件被多个目录引用
局限性:
- 不能创建目录的硬链接(会在目录树中创建一个环)
- 不能硬链接到其他磁盘分区中的文件
(因为 inode 号在特定文件系统中是唯一的,而不能跨文件系统)
符号链接(symbolic link)/软链接(softlink)
与硬链接完全不同
本身实际上是一个不同类型的文件
可能造成悬空引用(dangling reference)
链接 syscall API
- 创建链接:link()
- 删除链接:unlink()
文件系统
- 创建文件系统:mkfs
- 挂载文件系统:mount()
文件系统的组织
Windows设计
- 一个驱动器一棵树:A:, B:, C:, …
- 其他命名空间:Windows Driver Model, Registry
UNIX 的设计
目录树的拼接(挂载): 将一个目录解析为另一个文件系统的根
好处:将所有文件系统统一到一棵树中,而不是拥有多个独立的文件系统
镜像文件的挂载: loopback (回环) 设备
- 文件 = 磁盘上的虚拟磁盘
- 挂载文件 = 在虚拟磁盘上虚拟出的虚拟磁盘
目录结构: Filesystem Hierarchy Standard (FHS)
文件系统实现
数据结构(data structure)
磁盘映像整体结构
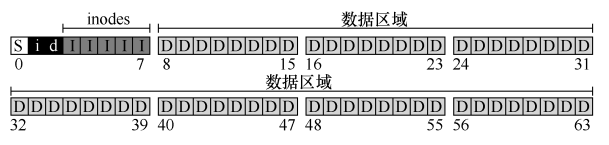
- 元数据(metadata)
- I: inode:记录每个文件的信息
- 分配结构(allocation structure):记录 inode 或数据块是空闲还是已分配
- i: inode 位图
- d: 数据位图
- S: 超级块(superblock):包含关于该特定文件系统的信息
inode数量,数据块、inode 表的开始位置,magic number(标识文件系统类型)
- 数据区域(data region)
文件组织:inode (index node)
如何计算inode在磁盘上的位置?
文件的低级名称(low-level name):每个 inode 都由一个数字(称为 inumber)隐式引用
给定一个 inumber,能够直接计算磁盘上相应inode节点的位置:
$$
blk = (inumber * sizeof(inode_t)) / blockSize;\
sector = ((blk * blockSize) + inodeStartAddr) / sectorSize;
$$
设计 inode 时,如何引用数据块的位置?
- 一种简单的方法:在inode 中有一个或多个直接指针(磁盘地址)(对大文件不友好)
- 使用链表(linked list): 一个 inode 中,只有一个指针,指向文件的第一个块
用链表存储数据:两种设计的权衡- 在每个数据块后放置指针
- 实现简单、无须单独开辟存储空间
- 数据的大小不是 $2^k$; 单纯的 lseek 需要读整块数据
- 对于某些工作负载表现不佳:读取文件的最后一个块/随机访问
- 将指针集中存放在文件系统的某个区域
- 局部性好;lseek 更快
- 集中存放的数据损坏将导致数据丢失
- 例子:文件分配表(File Allocation Table,FAT)文件系统
- 在每个数据块后放置指针
- 多级索引(multi-level index):间接指针(indirect pointer)
- 指向包含更多指针的块,每个指针指向用户数据
- 支持更大的文件:双重间接指针(double indirect pointer),三重间接指针(triple indirect pointer)
(最灵活的,但是每个文件使用大量元数据) - 例子:Linux ext2 和 ext3,NetApp 的 WAFL,以及原始的 UNIX 文件系统
- 使用范围(extent):一个磁盘指针加一个长度
- 通常允许多个范围(分配文件时可能无法找到连续的磁盘可用空间块)
(不够灵活但更紧凑) - 例子:SGI XFS 和 Linux ext4
- 通常允许多个范围(分配文件时可能无法找到连续的磁盘可用空间块)
目录组织
目录存储: 特殊的目录文件
目录有一个 inode,位于 inode 表中的某处,具有由 inode 指向的数据块
内容均为元数据(metadata),可以指向其他目录或文件
最基本:std::map <filename, inumber>
1 | struct dirent { |
删除一个文件(调用 unlink()):将对应条目的inumber置0
目录的组织:
- 线性目录列表
- B-tree:文件创建操作更快
- 例子:XFS
访问方法(access method)
从磁盘读取文件
- 使用open()系统调用打开文件
- 首先需要找到文件的 inode:遍历(traverse)路径名
- 读入根目录inode:根的 inumber 固定,UNIX 中为2
- 查找指向根目录数据块的指针
- 读取根目录,寻找相应的条目
一旦找到,也会找到下一个需要的 目录 的 inode 号 - 递归遍历路径名,直到找到所需的 inode
- 将找到的 inode读入内存
- 文件系统进行最后的权限检查
- 在每个进程的打开文件表中,为此进程分配一个文件描述符,并将它返回给用户
- 首先需要找到文件的 inode:遍历(traverse)路径名
- 发出read()系统调用,从文件中读取
- 查阅 inode 以查找这个块的位置,同时用新的最后访问时间更新 inode
- 读取的过程中更新此文件描述符在内存中的打开文件表,更新文件偏移量
open 导致的 I/O 量与路径名的长度成正比
写入磁盘
写入文件
- 使用open()系统调用打开文件
- 发出 write()调用以用新内容更新文件
- 将数据写入磁盘
- 可能会分配一个块:
决定将哪个块分配给文件,从而相应地更新磁盘的其他结构
在逻辑上会导致 5 个 I/O 操作:
- 一次读取数据位图(然后更新以标记新分配的块被使用)
- 一个写入位图(将它的新状态存入磁盘)
- 两次读取
- 写入 inode(用新块的位置更新)
- 写入真正的数据块本身
创建文件
- 分配一个 inode
- 在包含新文件的目录中分配空间
I/O 工作总量非常大:
- 一个读取 inode 位图(查找空闲 inode)
- 一个写入 inode 位图(将其标记为已分配)
- 一个写入新的 inode 本身(初始化)
- 一个写入目录的数据(将文件的高级名称链接到它的 inode 号)
- 一个读写目录 inode 以便更新它
如果目录需要增长以容纳新条目,则还需要额外的 I/O(即数据位图和新目录块)
降低文件系统 I/O 成本
使用系统内存(DRAM)来缓存重要的块
静态的内存划分(static partitioning)
引入了一个固定大小的缓存(fixed-size cache)来保存常用的块
优劣:
- 可确保共享资源,提供更可预测的性能,也更易于实现
- 文件高速缓存中的未使用页面不能被重新用于其他一些用途,可能导致浪费
动态划分(dynamic partitioning)
将虚拟内存页面和文件系统页面集成到统一页面缓存中(unified page cache)
优劣:
- 可以在虚拟内存和文件系统之间更灵活地分配内存,实现更好的利用率
- 实现起来可能会更复杂,并且可能导致空闲资源被其他用户占用
关于写入:
- 高速缓存不能减少写入流量(写入流量必须进入磁盘,才能实现持久)
- 写缓冲(write buffering)还是有许多优点:
- 可以合并写入IO,减少IO数量
- 可以调度(schedule)后续的 I/O,从而提高性能
- 一些写入可以通过拖延来完全避免
文件系统的崩溃一致性
崩溃一致性问题(crash-consistency problem,也可以称为一致性更新问题,consistent-update problem)
:由于崩溃而导致磁盘文件系统映像可能出现的许多问题:在文件系统数据结构中可能存在不一致性
理想的做法:将文件系统从一个一致状态原子地(atomically)移动到另一个状态
解决方法:
FSCK,文件系统检查程序(file system checker)
任务:
- 检查超级块:fsck 首先检查超级块是否合理,主要是进行健全性检查
- 目的:找到一个可疑的(冲突的)超级块
- 发现后可以决定使用超级块的备用副本
- 扫描空闲块:fsck 扫描 inode、间接块、双重间接块
- 目的:了解当前在文件系统中分配的块,生成正确版本的分配位图
- 如果位图和 inode之间存在任何不一致,则通过信任 inode 内的信息来解决
- 检查 inode 状态:检查每个 inode 是否存在损坏或其他问题
- 如果 inode 字段存在问题,不易修复,则 inode 被认为是可疑的,并被 fsck 清除,inode 位图相应地更新。
- 检查 inode 链接:fsck 验证每个已分配的 inode 的链接数
- 如果新计算的计数与 inode 中找到的计数不匹配,则必须采取纠正措施(通常是修复 inode 中的计数)
- 如果发现已分配的 inode 但没有目录引用它,则会将其移动到 lost + found 目录
- 检查重复指针:fsck 还检查重复指针,即两个不同的 inode 引用同一个块的情况
- 如果一个inode 明显不好,可能会被清除或复制指向的块,从而根据需要为每个inode 提供其自己的副本
- 检查坏块:检查坏块指针
- 如果指针显然指向超出其有效范围的某个指针,则被认为是“坏的”
- 发现后从 inode 或间接块中删除(清除)该指针
- 目录检查:fsck 对每个目录的内容执行额外的完整性检查
- 确保“.”和“..”是前面的条目,目录条目中引用的每个 inode 都已分配,并确保整个层次结构中没有目录的引用超过一次
问题: 性能很差,无法解决所有问题
日志记录(journaling,预写日志,write-ahead logging)
采用日志的文件系统:Cedar, Linux ext3 和 ext4, reiserfs, IBM 的 JFS, SGI 的 XFS 和 Windows NTFS
思路: 更新磁盘时,在覆写结构之前,首先写下一点小注记,把它写入一个结构,并组织成“日志”。
保证在更新(覆写)正在更新的结构期间发生崩溃时,能够返回并查看你所做的注记,然后重试
增加了更新时的工作量,但大大减少了恢复期间的工作量
细节参考: Linux ext3
软更新
仔细地对文件系统的所有写入排序,以确保磁盘上的结构永远不会处于不一致的状态。
写时复制(Copy-On-Write,COW)
永远不会覆写文件或目录。相反,它会对磁盘上以前未使用的位置进行新的更新。
在完成许多更新后,COW 文件系统会翻转文件系统的根结构,以包含指向刚更新结构的指针。
细节参考: 日志结构文件系统 LFS
基于反向指针的一致性(Backpointer-Based Consistency,BBC)
在写入之间不强制执行排序。
为了实现一致性,系统中的每个块都会添加一个额外的反向指针。
例如,每个数据块都引用它所属的inode。
访问文件时,文件系统可以检查正向指针(inode 或直接块中的地址)是否指向引用它的块,
从而确定文件是否一致。如果是这样,一切都肯定安全地到达磁盘,因此文件是
一致的。如果不是,则文件不一致,并返回错误。
乐观崩溃一致性(optimistic crash consistency)
尽可能多地向磁盘发出写入,并利用事务校验和(transaction checksum)的一般形式,
以及其他一些技术来检测不一致。
对于某些工作负载,这些乐观技术可以将性能提高一个数量级。但是对磁盘有特殊要求。
文件系统实例
第一个 UNIX 文件系统
磁盘数据结构:
- 超级块(S):包含有关整个文件系统的信息:卷的大小、有多少 inode、指向空闲列表块的头部的指针等等
- inode 区域:包含文件系统的所有 inode
问题:性能不佳
- 昂贵的定位成本:数据块与inode距离很远
- 碎片化(fragmented)严重:大文件分散存储,访问时影响性能
快速文件系统(Fast File System,FFS)
思路: 让文件系统的结构和分配策略具有“磁盘意识”,从而提高性能
- 将磁盘划分为一些分组,称为柱面组
- 在同一组中放置多个文件,以确保先后访问这些文件不会导致穿越磁盘的长时间寻道
组织结构: 柱面组(cylinder group,或块组block group)
每个柱面组的结构:
- 超级块(super block)的一个副本:提高可靠性
- inode 位图(inode bitmap,ib)和数据位图(data bitmap,db):记录分配
文件和目录在磁盘上的放置: 利用局部性
- 目录的放置: 找到分配数量少的柱面组(希望跨组平衡目录)和大量的自由 inode(希望随后能够分配一堆文件),并将目录数据和 inode 放在该分组中
- 文件的放置
- 确保(在一般情况下)将文件的数据块分配到与其 inode 相同的组中
- 防止 inode 和数据之间的长时间寻道
- 将位于同一目录中的所有文件,放在它们所在目录的柱面组中
- 确保(在一般情况下)将文件的数据块分配到与其 inode 相同的组中
- 例外:大文件的放置(摊销寻道时间)
- 将一定数量的块分配到第一个块组(前 12 个直接块)
- 文件的下一个块放在另一个不同的块组中,依此类推
(每个后续的间接块,以及它指向的所有块)
trade-off:大块大小
大块越大,可利用的局部性越差,但磁盘访问性能更好
优化创新:
- 子块(sub-block):容纳小文件时不会浪费整个 4KB 块
- 针对性能进行优化的磁盘布局:参数化
找出磁盘的特定性能参数,并利用它们来确定准确的交错布局方案 - 允许长文件名
- 引入符号链接
- 引入原子rename()操作,用于重命名文件
FAT (File Allocation Table)文件系统
需求分析: 相当小的文件系统
- 目录中一般只有几个、十几个文件
- 文件以小文件为主 (几个 block 以内)
文件的实现
struct block* 的链表: 集中保存所有指针
FAT-12/16/32(FAT entry,即“next指针”的大小)
本身没有 inode,而是存储关于文件的元数据的目录条目
,并且直接指向所述文件的第一个块,这导致不可能创建硬链接
目录的实现
目录文件: 32-byte 定长目录项的集合
优劣
- 适合小文件
- 不适合大文件的随机访问:大量的next操作
- 使用时间久会产生碎片 (fragmentation)
- 维护若干个 FAT 的副本防止元数据损坏 (额外的开销)
ext2 / UNIX 文件系统
改进思路:
- 按对象方式集中存储文件/目录元数据
- 增强局部性 (更易于缓存)
- 支持链接
- 为大小文件区分 fast/slow path
- 小的时候应该用数组
- 大的时候应该用树:快速的随机访问
ext2: 磁盘镜像格式: in ext2.h
磁盘被分成块组,每个块组都有一个 inode和数据位图以及 inode 和数据块
ext2 inode: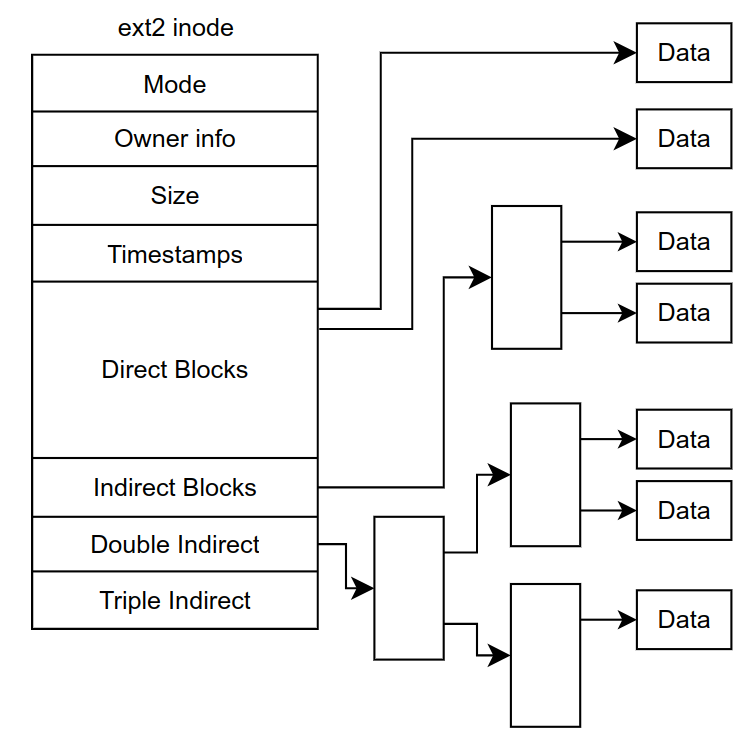
ext2 目录:
目录文件:与 FAT 本质相同,在文件上建立目录的数据结构
优劣
- 局部性与缓存:通过内存缓存减少读/写放大,inode 在磁盘上连续存储,便于缓存/预取
- 大文件的随机读写性能提升明显 (O(1)O(1))
- 支持链接 (一定程度减少空间浪费)
- 依然有碎片的问题
- 存储 inode 的数据块损坏是很严重的
Linux ext3 文件系统
一种流行的日志文件系统,大多数磁盘上的结构与 Linux ext2 相同,区别只是日志的存在

基础协议:数据日志(data journaling)

日志内容:
- 事务开始块(TxB):有关此更新的信息
包括对文件系统即将进行的更新的相关信息以及某种事务标识符(transaction identifier,TID) - 中间的 3 个块:包含块本身的确切内容,属于物理日志
- 事务结束块(TxE):也会包含 TID
日志类型:
- 物理日志(physical logging):将更新的确切物理内容放在日志中
- 逻辑日志(logical logging):在日志中放置更紧凑的更新逻辑表示
- 例如,“这次更新希望将数据块 Db 追加到文件 X”
- 有点复杂,但可以节省日志中的空间,并可能提高性能
更新过程:
- 日志写入:将事务的内容(包括 TxB、元数据和数据)写入日志,等待这些写入完成。
- 日志提交:将事务提交块(包括 TxE)写入日志,等待写完成,事务被认为已提交(committed)
将TxE单独写入的原因:日志的各个块的写入可能不是顺序的(磁盘调度导致) - 加检查点:将更新内容(元数据和数据)写入其最终的磁盘位置。
崩溃恢复(recover): 重新执行日志(redo logging)
- 系统引导时,文件系统将扫描日志,并查找已提交到磁盘的事务
- 重放(replayed,按顺序)这些已提交的事务
优化:
- 批处理日志更新
- 解决的问题:避免对磁盘的过多的写入流量
- 将所有更新缓冲到全局事务中:将需要修改的块标记为脏,并将它们添加到块列表中,形成当前的事务
- 当最后应该将这些块写入磁盘时,写入单个全局事务
- 循环日志(circular log)
- 解决的问题:
(1) 日志越大,恢复时间越长;
(2) 当日志已满(或接近满)时,不能向磁盘提交进一步的事务 - 一旦事务被加检查点,文件系统应释放它在日志中占用的空间,允许重用日志空间。
- 解决的问题:
- 有序日志(ordered journaling,或称为元数据日志,metadata journaling)
- 解决的问题:每次写入都要写入数据2次(1次日志,1次实际位置),带宽降低一半
优化:有序日志(ordered journaling,或称为元数据日志,metadata journaling)

强制先写入数据,文件系统可以保证指针永远不会指向垃圾
崩溃一致性的核心:“先写入被指对象,再写入指针对象”
写入协议:
- 数据写入:将数据写入最终位置,等待完成(与步骤2顺序可换)
- 日志元数据写入:将开始块和元数据写入日志,等待写入完成
- 日志提交:将事务提交块(包括 TxE)写入日志,等待写完成,认为事务(包括数据)已提交(committed)
- 加检查点元数据:将元数据更新的内容写入文件系统中的最终位置
- 释放:稍后,在日志超级块中将事务标记为空闲
块重复使用的问题: 有块先被删除后被重用,导致元数据日志在崩溃恢复时会先删除重用时写的数据
解决方案:删除时使用撤销(revoke)记录,重放日志时任何撤销类的记录不会被重放
Linux ext4
对ext3的优化: 日志写入
将事务写入日志时,在开始和结束块中包含日志内容的校验和。
如果在恢复期间,文件系统发现计算的校验和与事务中存储的校验和不匹配,则可以断定
在写入事务期间发生了崩溃,从而丢弃了文件系统更新。
优点:
- 可以实现更快的通用情况性能
- 系统的可靠性提高了
因为来自日志的任何读取都受到校验和的保护
日志结构文件系统(Log-structured File System,LFS)
- 专注于写入性能,并尝试利用磁盘的顺序带宽。
- 在常见工作负载上表现良好(不仅写出数据,还经常更新磁盘上的元数据结构)
- 可以在 RAID 和单个磁盘上运行良好
写入磁盘时:
- 将所有更新(包括元数据)缓冲在内存段中
- 当段已满时,它会在一次长时间的顺序传输中写入磁盘,并传输到磁盘的未使用部分。
- 永远不会覆写现有数据,而是始终将段写入空闲位置
如何顺序而高效地写入?写入缓冲(write buffering)
目的:向驱动器发出大量连续写入(或一次大写入),防止两次写入之间的其他操作导致额外的磁盘旋转时间
思路:在写入磁盘之前,LFS 会跟踪内存中的更新。收到足够数量的更新时,会立即将它们写入磁盘,
从而确保有效使用磁盘。
段(segment):一次写入的大块更新,用来对写入进行分组的大块。
段的大小选择:取决于磁盘本身
$$ D = \dfrac{F}{1-F} \times R_{peak} \times T_{position} $$
(定位时间 $T_{position}$,峰值带宽 $R_{peak}$,有效带宽百分比 $F$,传输数据大小 $D$)
如何查找 inode?inode 映射(inode map,imap)
问题:由于LFS永远不会覆盖,因此最新版本的 inode会不断移动
思路:在 inode 号和 inode 之间引入了一个间接层(level of indirection)
imap 数据结构:
- 将 inode号作为输入,并生成最新版本的 inode 的磁盘地址
- 每次将 inode 写入磁盘时,imap 都会使用其新位置进行更新
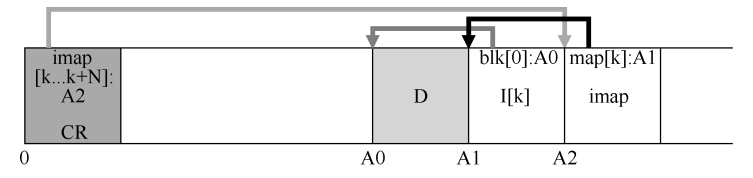
imap的驻留位置:放在它写入所有其他新信息的位置旁边
如何找到 inode 映射块? LFS 在磁盘上只有一个固定的位置,称为检查点区域(checkpoint region,CR)
- 包含指向最新的 inode 映射片段的指针(即地址)
- 因此可以通过首先读取 CR 来找到 inode 映射片段
- 仅定期更新(例如每 30s 左右),因此性能不会受到影响
- 始终位于磁盘的开头,地址为 0
inode 映射还解决了 LFS 中存在的另一个严重问题:递归更新问题(recursive update problem)
递归更新问题(recursive update problem):
任何永远不会原地更新的文件系统(例如 LFS)都会遇到该问题
每当更新 inode 时可能导致对指向该文件的目录的更新,然后必须更改该目录的父目录,依此类推,一路沿文件系统树向上。imap可以使文件更新时,对应的inumber在imap中保持不变,即imap改变的是inumber到inode的映射
旧数据清理
版本控制文件系统(versioning file system):
可以保留那些旧版本并允许用户恢复旧文件版本。
这样的文件系统称为版本控制文件系统(versioning file system),因为它跟踪文件的不同版本。
LFS 清理程序: 按段工作,从而为后续写入清理出大块空间
- 定期读入许多旧的(部分使用的)段,确定哪些块在这些段中存在
- 写出一组新的段,只包含其中活着的块,从而释放旧块用于写入
预期清理程序读取 M 个现有段,将其内容打包(compact)到 N 个新段(其中 N < M),
然后将 N 段写入磁盘的新位置。然后释放旧的 M 段,文件系统可以使用它们进行后续写入。
机制:如何确定块的死活?
为描述每个块的每个部分添加一些额外信息,包括其 inode 号及其偏移量,
该信息记录在一个数据结构中,位于段头部,称为段摘要块(segment summary block)
对于位于地址 A 的磁盘上的块 D
- 查看段摘要块并找到其 inode 号 N 和偏移量 T
- 查看最新 imap 以找到 N 所在的位置,并从磁盘读取 N
- 利用偏移量 T,查看 inode,读取此文件的第 T 个块在磁盘上的位置
- 如果它指向磁盘地址 A,则块 D 是活的
更快的办法:修改文件后,LFS 会增加其版本号(version number),并在 imap 中记录新版本号。通过在磁盘上的段中记录版本号,LFS 可以简单地通过将磁盘版本号与 imap 中的版本号进行比较,跳过上述较长的检查,从而避免额外的读取。
策略:要清理哪些块,何时清理?
确定何时清理比较容易:
- 周期性
- 空闲时间
- 磁盘已满时
确定清理哪些块更具挑战性:
分离冷热段(一种方法):尽快清理冷段,延迟清理热段
崩溃恢复
写入CR: 如何确保 CR 更新以原子方式发生?
保留了两个CR,每个位于磁盘的一端,并交替写入它们。
- 首先写出一个头(带有时间戳)
- 然后写出 CR 的主体
- 最后写出最后一部分(带有时间戳)
如果系统在 CR 更新期间崩溃,可以通过查看一对不一致的时间戳来检测到这一点。
LFS 将始终选择使用具有一致时间戳的最新 CR,从而实现 CR 的一致更新。
写入段: 前滚(roll forward)技术
在日志(log)中组织写入,即指向头部段和尾部段的检查点区域,并且每个段指向要写入的下一个段
- 从最后一个检查点区域开始,找到日志的结尾(包含在 CR 中)
- 使用它来读取下一个段,并查看其中是否有任何有效更新
- 如果有,LFS 会相应地更新文件系统,从而恢复自上一个检查点以来写入的大部分数据和元数据。